(D)DoS and Application Security: The Complete Guide
Table of contents
This is the index and reading guide for a three-part series on denial-of-service and application security. The first two parts cover availability attacks — a service being made unreachable or unusable — at levels most people don’t associate with the term “DDoS”: the business level (losing the people who run the service), the social level (manipulating the humans behind it), the informational level (reputational disruption), and finally the technical level most readers expect (network floods, BGP hijacking, Layer 7 exhaustion). The third part is a deliberate step sideways, into application-layer attacks — SQL Injection, Log4Shell, the OWASP Top 10 — that threaten confidentiality and integrity instead of availability.
What recurs across all three parts is that “denial of service” is used here in a broader sense than the network-security definition most people default to. The series follows one thread from the top down: a business-level disruption and a SYN flood are the same category of harm — the service stops delivering value to the people who depend on it — even though one is solved with HR and trust and the other with rate limiting and upstream scrubbing. The technical mechanism is only ever half the story; the other half is who is affected and what it costs them.
This series is fairly broad, but it is not, and cannot be, complete. Every use case carries its own constraints — a regulatory obligation, a legacy dependency, a team’s operational maturity, an attack surface not covered here — that can turn a general practice into the wrong call for that specific situation. Treat this guide as a starting point, not a checklist to apply unmodified: it is always worth discussing your own use case with people who know it before committing to any of the choices below.
How to read this guide🔗
If you’re weighing what “denial of service” means for a business you’re responsible for, start with Part 1. If you’re hardening infrastructure against network- or application-layer floods, go to Part 2. If your concern is data theft or remote code execution rather than uptime, Part 3 is a different threat model entirely and worth reading on its own.
- Part 1 — Non-technical: Business, Social, Informational: denial of service beyond the network layer
- Part 2 — Technical: Network floods, BGP hijacking, Layer 7, Resilience: availability attacks and their mitigations
- Part 3 — Application Security: SQL Injection, Log4Shell, and OWASP Top 10 — confidentiality and integrity, not availability
Part 1 — Non-technical: Business, Social, Informational🔗
Audience: decision makers and business stakeholders.
Part 1 argues that a service can be denied without a single packet being sent against it. At the business level, an attacker doesn’t need to break anything technical — driving away or poaching the people who understand the setup achieves the same outcome, and recovery is slower because the knowledge, not the infrastructure, is what’s gone. At the social level, the target is the individual administrator, manipulated through trust rather than a technical exploit. At the informational level, spreading damaging claims about a company’s state can end customer relationships just as effectively as an outage would. The common thread is that all three levels are denial-of-service in effect, even though none of them touch a server.
Key takeaways:
- A “denial of service” against the people who run a service — driving them out through a better offer elsewhere, or simply attrition — can be more damaging than a technical outage, because the knowledge required to recover leaves with them.
- Social engineering against administrators works by exploiting trust and emotion, not a technical vulnerability; the defense is a high-trust culture where people feel safe raising “something feels wrong.”
- Informational attacks — spreading claims that a company is failing — can end customer relationships without touching any system, and are hard to counter once social media amplifies them.
- AI-assisted social engineering is already used at scale in phishing and targeted manipulation campaigns; prompt injection and model manipulation are an emerging attack surface on AI systems themselves.
- Aggressive AI crawler traffic is a modern variant of the same problem: distributed, high-volume requests that are functionally indistinguishable from a volumetric DDoS, mitigated with the same tools (rate limiting, WAF, connection throttling).
Read Part 1 — Non-technical overview →
Part 2 — Technical: Network floods, BGP hijacking, Layer 7, Resilience🔗
Audience: network and platform engineers.
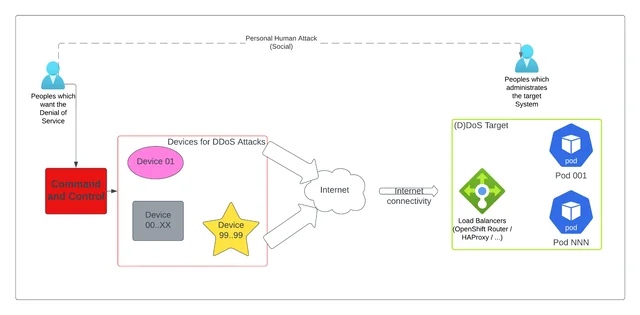
Part 2 is the part most readers expect from a “DDoS” post: the mechanisms that make a service technically unreachable. It works up the stack — Layer 3/4 floods that exhaust bandwidth or connection tables before traffic reaches the application, BGP hijacking that reroutes traffic away from the target at the internet-routing level, and Layer 7 attacks that consume application resources with individually legitimate but collectively expensive requests. It closes on operational resilience — geographic redundancy, anycast, and automated failover — as the layer that limits damage when the other mitigations aren’t enough on their own.
Key takeaways:
- SYN floods, UDP floods, and amplification attacks (DNS/NTP amplification factors of 10-100x) target bandwidth or connection-table capacity, not the application itself — filtering and scrubbing happen before traffic reaches the origin.
- TLS termination is itself a DDoS surface: the handshake is computationally asymmetric, cheap for the client and expensive for the server; TLS 1.3 removes the renegotiation-attack variant but connection-rate limiting at the load balancer is still needed.
- BGP hijacking reroutes traffic at the routing level by announcing a more specific prefix; RPKI lets route originators sign announcements so downstream routers can reject invalid ones, though adoption is still not universal.
- Layer 7 attacks — expensive endpoints, Slowloris, GraphQL query complexity, LLM inference abuse — are defended with rate limiting, connection caps, caching, and a WAF that is actually configured for the specific application, not left on default rules.
- No single mitigation is sufficient against a sustained attack; the effective posture combines upstream scrubbing, application-layer rate limiting, and geographic distribution, planned before an attack rather than during one.
Read Part 2 — Technical deep dive →
Part 3 — Application Security🔗
Audience: application developers and security engineers.
Part 3 explicitly steps away from availability. SQL Injection, Log4Shell, and the rest of the OWASP Top 10 extract data or execute code — they don’t typically take a service down, so the mitigations that work for Parts 1 and 2 don’t apply here. The more consequential argument in this part is about timing: the gap between a latent vulnerability existing and someone finding it used to be measured in years — Log4Shell sat undiscovered since 2013 before surfacing in 2021. AI-assisted vulnerability discovery (Google’s Big Sleep, OpenAI’s Aardvark, DARPA’s AIxCC, XBOW, and Anthropic’s own internal findings) is compressing that gap to weeks, in real production codebases including SQLite, OpenSSH, and GnuTLS — not just typical web-application bugs.
Key takeaways:
- SQL Injection, Log4Shell, and the OWASP Top 10 threaten confidentiality and integrity, not availability — a successful attack extracts or modifies data rather than making the service unreachable, so it needs a different response than a DDoS does.
- Log4Shell (CVE-2021-44228) existed in deployed code since 2013 and went unnoticed for eight years — the historical norm was that obscure latent bugs took years to surface.
- AI-assisted discovery tools have already found real, previously-unknown vulnerabilities in production software: Google’s Big Sleep found a stack buffer underflow in SQLite in 2024 and CVE-2025-6965 (already known to attackers) in 2025; OpenAI’s Aardvark scanned 1.2 million commits and surfaced 792 critical findings.
- The shrinking discovery window makes “keep dependencies updated” the primary mitigation against a class of threats now being found faster than most organizations patch, not just routine hygiene.
- Input validation defined against actual business logic, and a WAF configured with custom rules rather than left on defaults, remain the two most effective controls — both are frequently deployed in name only.
Read Part 3 — Application Security →
The through-line🔗
Availability versus confidentiality/integrity are different threat models. Parts 1 and 2 are about a service staying reachable; Part 3 is about what happens once someone reaches it with bad intent. Rate limiting a login endpoint helps against credential-stuffing volume, but it does nothing against a well-crafted SQL Injection payload sent once. Treating “security” as one undifferentiated problem leads to solving the wrong half of it.
Business impact and technical mechanism are two sides of one problem. A SYN flood and losing the one engineer who understands the deployment are both, in effect, a denial of service — the technical detail changes, but the consequence (the service stops delivering value to the people who need it) does not. Reading the business/social framing in Part 1 alongside the packet-level detail in Part 2 makes both easier to justify to the people who fund the mitigation.
Defense is layered because the attack surface is layered. Business-level resilience means cross-training and documentation so no single person’s departure is catastrophic. Social-level resilience means a culture where “this feels wrong” gets raised. Network-level resilience means scrubbing and geographic redundancy. Application-level resilience means input validation and dependency hygiene. None of these substitutes for another.
Related deep-dives🔗
Log retention and analysis are often part of incident response for both DDoS and application-security events — see the Elasticsearch vs. OpenSearch vs. Loki vs. Quickwit vs. ClickHouse comparison for choosing a backend that can hold and query that evidence.
Where to start🔗
If you have no strong prior, start with the non-technical framing — it sets up why the technical and application-security parts matter to more than just the engineers implementing them. If you already know you’re dealing with an availability incident or an application vulnerability specifically, jump straight to Part 2 or Part 3.