9 posts in category ai
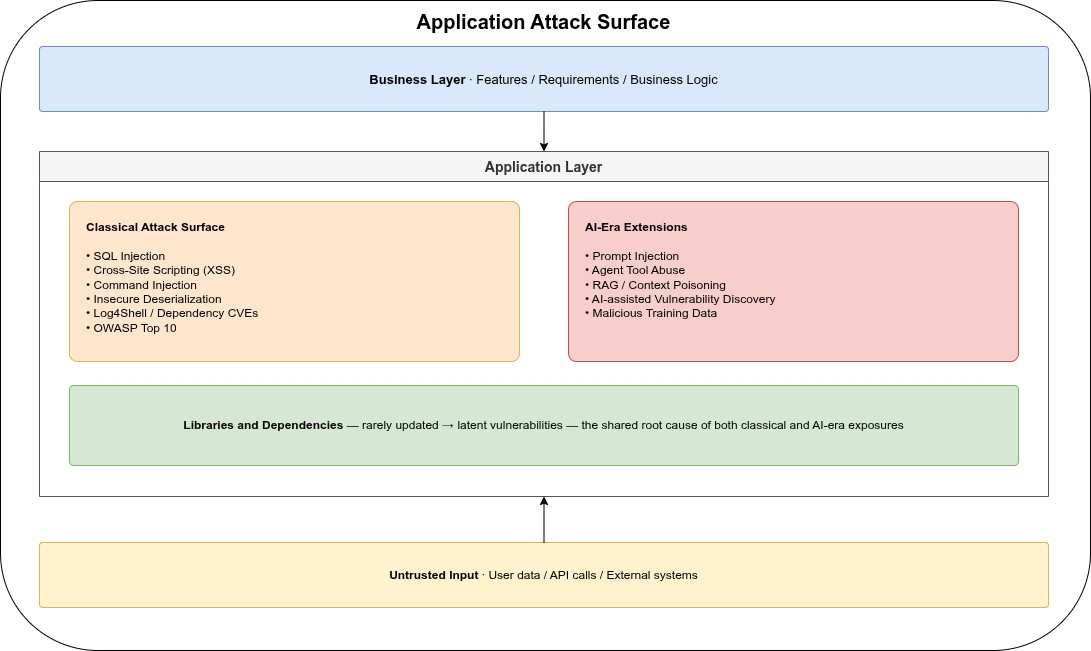
What is Application Security
Application security: SQL Injection, Log4Shell, OWASP Top 10, and Input Validation — attacks that affect confidentiality and integrity, not availability.

How I work with Claude Code
My practical workflow for using Claude Code: project-level rules, persistent memory across sessions, plan mode, and what needs scaffolding to work well.
LLM Inference on OVH MKS: Connect IDEs and Web UIs
Connect Continue.dev, Zed, Cline, Open WebUI, and ownCloud Infinite Scale to a self-hosted vLLM endpoint on OVH MKS. Per-client setup guide. Part 5 of 6.
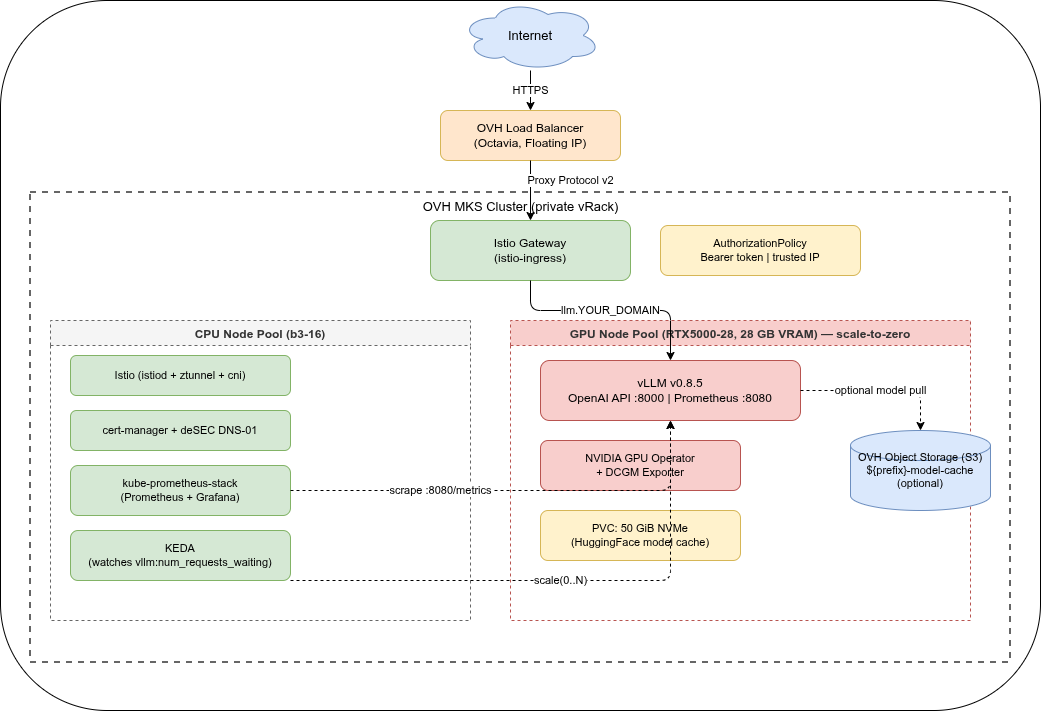
LLM Inference on OVH MKS: Terraform, Ansible, and Deployment
Provision an OVH MKS GPU node pool with Terraform, deploy vLLM, Istio, and cert-manager with Ansible, and walk through a first deployment. Part 2 of 6.
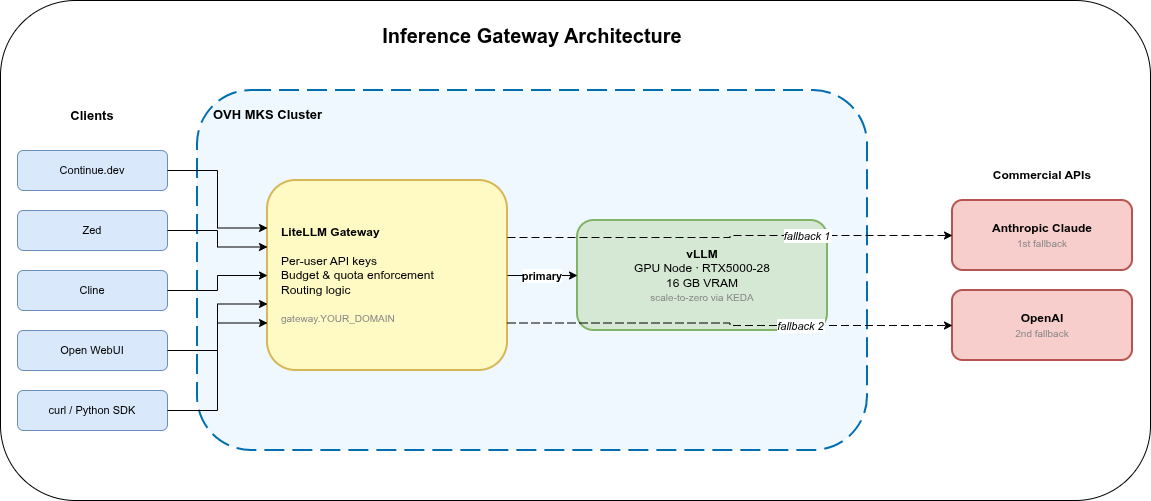
LLM Inference on OVH MKS: LiteLLM API Gateway
LiteLLM gateway on top of vLLM: per-user API keys, budget limits, and automatic fallback to commercial APIs when the local GPU node is cold. Part 6 of 6.
LLM Inference on OVH MKS: The Complete Guide
Index and reading guide for a six-part series on self-hosting LLM inference on OVH MKS — vLLM, GPU node pools, Terraform, observability, clients, and a gateway.
LLM Inference on OVH MKS: Introduction
When to self-host an LLM on Kubernetes, why vLLM, and what the stack looks like on OVH MKS. Covers use cases, cost framing, and architecture. Part 1 of 6.
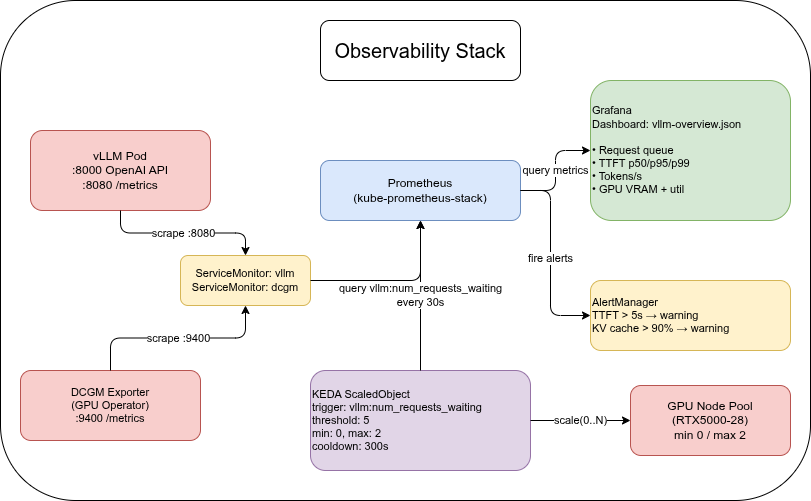
LLM Inference on OVH MKS: Prometheus, Grafana, and KEDA
Scrape vLLM and DCGM metrics with kube-prometheus-stack, visualise TTFT and tokens/s in Grafana, and autoscale to zero with KEDA. Part 4 of 6.
LLM Inference on OVH MKS: Models, AWQ, and OpenAI API
Which models fit on a 16 GB GPU, why AWQ is required for 7B+ models on the RTX5000-28, and how to use the OpenAI-compatible API from Python. Part 3 of 6.