LLM Inference auf OVH MKS: Einführung
Dieser Beitrag behandelt den Entscheidungskontext für Self-Hosting von LLM-Inference auf OVH MKS: wann es sich lohnt, wie der Stack aussieht und was es kostet. Teil 2 geht durch das Terraform- und Ansible-Setup.
Serien-Navigation: Die restlichen Teile dieser Serie sind aktuell nur auf Englisch verfügbar.
- Vollständiger Guide: LLM Inference on OVH MKS: The Complete Guide
- Teil 1 — Einführung (dieser Beitrag)
- Teil 2 — Terraform, Ansible und Deployment
- Teil 3 — Modelle, AWQ und OpenAI-API
- Teil 4 — Prometheus, Grafana und KEDA
- Teil 5 — IDEs und Web-UIs anbinden
- Teil 6 — Self-hosted LLM Gateway
Das begleitende Repository liegt unter codeberg.org/nis-aleks/ovh-llm-inference.
Warum Self-Hosting?🔗
Kommerzielle LLM-APIs (OpenAI, Anthropic, Google) sind einfach zu nutzen, gut gepflegt und erfordern keine eigene Infrastruktur. Self-Hosting lohnt sich, wenn einer oder mehrere der folgenden Punkte zutreffen:
Datenschutz und Compliance. Anfragen an eine kommerzielle API verlassen die eigene Infrastruktur. Für regulierte Branchen (Gesundheitswesen, Finanzen, Recht) oder bei der Verarbeitung vertraulicher Geschäftsdaten kann es unabhängig von den Datenverarbeitungsvereinbarungen des Anbieters eine harte Anforderung sein, Inference auf der eigenen Infrastruktur zu behalten.
Kosten bei Skalierung. Kommerzielle APIs werden pro Token abgerechnet — die Kosten skalieren mit dem Anfragevolumen. Ein selbst gehosteter Endpunkt hat feste Stundenkosten unabhängig vom Durchsatz. Je nach Volumen und Modell kann beides günstiger sein; der Break-even-Punkt variiert.
Modellwahl. Das Open-Weights-Ökosystem (LLaMA, Mistral, Qwen, Gemma und Tausende Fine-Tunes auf HuggingFace) enthält Modelle, die über keine kommerzielle API verfügbar sind. Wer ein domänenspezifisches Fine-Tune, ein Modell mit einer bestimmten Lizenz oder schlicht ein Modell braucht, das ein Anbieter nicht führt, kommt an Self-Hosting nicht vorbei.
Anbieterunabhängigkeit. API-Preise, Rate-Limits und Modellverfügbarkeit können sich ändern. Ein selbst gehosteter Endpunkt gibt volle Kontrolle über Modellversion und Serving-Infrastruktur.
Trifft nichts davon auf die eigene Situation zu, kann eine kommerzielle API der einfachere Weg sein.
Diese Serie behandelt das Servieren vortrainierter Modelle, nicht Training oder Fine-Tuning. Modell-Gewichte werden vom HuggingFace Hub heruntergeladen und direkt von vLLM geladen. Selbst das Training eines kleinen 7B-Modells erfordert deutlich mehr GPU-Speicher (Optimizer-States, Gradienten) und anderes Tooling (PyTorch, DeepSpeed, FSDP) — das ist hier bewusst außerhalb des Scopes.
Ein OVH-RTX5000-28-GPU-Node ist eine kostenpflichtige Instanz, abgerechnet pro Stunde (≈€0,36/h als MKS-Node-Pool, Stand Mitte 2026 — aktuelle Preise unter ovhcloud.com prüfen). Ein GPU-Node 24/7 laufen zu lassen kostet zu On-Demand-Raten rund €263/Monat. OVH bietet Savings Plans, die das reduzieren können — aktuelle Rabatte auf der OVH-Savings-Plans-Seite prüfen. Mit Scale-to-Zero wird der GPU-Node nur abgerechnet, wenn Inference-Anfragen anstehen — Leerlaufzeit ist kostenlos.
Zu beachten ist auch, dass das Standard-OVH-Public-Cloud-Kontingent nicht allzu viele GPU-Flavors enthält. Vermutlich muss vor der Terraform-Provisionierung des GPU-Node-Pools eine Kontingenterhöhung beantragt werden — in der Praxis war dafür eine einmalige Zahlung von rund €200 zur Kontovalidierung nötig. Das vorab einplanen.
Warum OVH?🔗
Diese Serie baut auf der OVH-MKS-Infrastruktur aus der SigNoz-Serie auf — das Terraform-Netzwerkmodul und die Ansible-Rollen für cert-manager und Istio werden hier unverändert wiederverwendet. Neu sind der GPU-Node-Pool und die vLLM-Rolle.
Zwei Eigenschaften sind für dieses spezielle Autoscaling-Setup relevant:
- GPU-Node-Pools mit Cluster Autoscaler — Teil 4s Scale-to-Zero verlässt sich darauf, dass der Cluster-Autoscaler der Cloud GPU-Nodes bei Bedarf bereitstellt und wieder freigibt. OVH MKS unterstützt das nativ. Die vollständige GPU-Flavor-Tabelle für GRA9 steht in Teil 3.
- Europäischer Datenstandort — OVH-GPU-fähige MKS-Regionen umfassen GRA9 und SBG5, wodurch Daten in der EU bleiben, ohne über US-Infrastruktur geroutet zu werden.
Die Ansible-Rollen (vLLM, KEDA, GPU Operator) sind auf andere Managed-Kubernetes-Anbieter (EKS, GKE, AKS) übertragbar. Das Terraform braucht Anpassungen für die jeweilige Node-Pool-API.
Wo dieser Stack passt🔗
| Use Case | Passform |
|---|---|
| Coding-Assistent für ein Team von 5–20 | ✓ |
| Interner Chatbot oder RAG (Retrieval-Augmented Generation) über private Dokumente | ✓ |
| Regulierte Daten: Gesundheitswesen, Finanzen, Recht | ✓ — Inference bleibt auf der eigenen Infrastruktur |
| Testen von Open-Weight-Modellvarianten oder Fine-Tunes | ✓ |
| Komplexes Reasoning, agentische Workflows (mit größeren Modellen) | ✓ — Wechsel auf 32B+ auf einem V100S- oder H100-Flavor |
| Öffentlicher Dienst mit 100+ gleichzeitigen Nutzern | braucht eine Multi-Node-GPU-Flotte |
Ein selbst gehostetes 8B-Modell ist kein Ersatz für Claude oder GPT-4o. Der Wert dieses Setups liegt in Datenlokalität, Infrastrukturkontrolle und planbaren Fixkosten — nicht in der Ausgabequalität. Bei einem 8B-Modell ist die Ausgabequalität ein echter Trade-off: komplexes Reasoning, lange Multi-Step-Workflows und nuanciertes Schreiben sind Bereiche, in denen Frontier-APIs einen klaren Vorteil haben. Ein größeres selbst gehostetes Modell (32B+ AWQ auf einem V100S oder H100) verändert diese Rechnung deutlich — das ist aber eine eigene Kosten- und Infrastrukturdiskussion. Die Use Cases oben sind dort, wo der 8B-Trade-off für Self-Hosting spricht.
Das Standardmodell ist 8B — je nach Use Case anpassen. Die Serie nutzt hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4 als kosteneffizienten Ausgangspunkt. Ein quantisiertes 8B-Modell ist bei Multi-Step-Reasoning und komplexen agentischen Aufgaben spürbar schwächer als Frontier-Modelle (GPT-4o, Claude). Die Infrastruktur selbst ist nicht der limitierende Faktor: derselbe Stack betreibt Qwen2.5 32B AWQ auf einem V100S (32 GB) oder LLaMA 3.1 70B AWQ auf einem H100 (80 GB) mit einer einzigen Flavor-Änderung in terraform.tfvars. Teil 3 enthält die vollständige GPU-Flavor-Tabelle und den VRAM-Guide.
Der limitierende Faktor ist die Modellwahl, nicht die Infrastruktur. Der Wechsel des GPU-Flavors beginnt mit einer Zeile in terraform/envs/staging.tfvars plus modellspezifischen vLLM-Einstellungen. Teil 3 behandelt das im Abschnitt Changing the model.
Kosteneinordnung. Pro-Nutzer-Coding-Assistent-Abos (GitHub Copilot, JetBrains AI) kosten grob €10–€20/Nutzer/Monat. Bei 5 Entwicklern sind das €50–€100/Monat; bei 10 Entwicklern €100–€200/Monat. Ein selbst gehosteter Endpunkt mit Nutzung während der Geschäftszeiten (8 h/Tag) kostet unabhängig von der Teamgröße ≈€86/Monat — Fixkosten statt linearer Pro-Nutzer-Kosten. Teil 4 enthält die vollständige Kostenaufschlüsselung.
Zeitplanung nach Geschäftszeiten. Da der GPU-Node nur abgerechnet wird, solange er existiert, lassen sich die Kosten weiter senken, indem man das vLLM-Deployment morgens hochskaliert und abends wieder auf null zurückfährt — der Cluster Autoscaler stellt den GPU-Node automatisch bereit und gibt ihn wieder frei. Vor und nach den Arbeitszeiten sollte man rund eine Stunde Puffer einplanen: GPU-Node-Provisionierung dauert 5–15 Minuten, und vLLM braucht weitere 2–3 Minuten, um die gecachten Modell-Gewichte zu laden. Die Tabelle unten nutzt Österreich als Beispiel (13 Feiertage, 40 h/Woche, 247 Arbeitstage/Jahr):
| Szenario | h/Jahr | €/Jahr | ≈€/Monat |
|---|---|---|---|
| 24/7 | 8.760 | €3.154 | €263 |
| 8 h/Tag, 365 Tage | 2.920 | €1.051 | €88 |
| Nur Geschäftszeiten (247 Tage × 10 h) | 2.470 | €889 | €74 |
Hoch- und Herunterskalieren mit zwei Befehlen:
kubectl -n vllm scale deployment vllm --replicas=1 # morgens: GPU-Node bereitstellen
kubectl -n vllm scale deployment vllm --replicas=0 # abends: GPU-Node freigebenBeides lässt sich in einem Kubernetes-CronJob für vollautomatische Zeitplanung verpacken.
Was ist vLLM?🔗
vLLM ist eine Open-Source-LLM-Inference-Engine, optimiert für hohen Durchsatz und niedrige Latenz. Wichtige Eigenschaften:
- OpenAI-kompatible REST-API — funktioniert als Drop-in-Ersatz für Clients, die das OpenAI-Python-SDK oder
curlnutzen - PagedAttention für effiziente KV-Cache-Nutzung (bis zu 3× höherer Durchsatz vs. naives Serving)
- Unterstützt HuggingFace-Modelle, AWQ/GPTQ-Quantisierung, LoRA-Adapter
- Legt nativ Prometheus-Metriken offen (Request-Queue-Tiefe, TTFT (Time To First Token), Tokens/s, GPU-Cache-Nutzung)
vLLM vs. Alternativen🔗
| Tool | Am besten für |
|---|---|
| vLLM | Multi-User-Produktions-API, Kubernetes, hoher Durchsatz |
| Ollama | Lokale Maschine, einzelner Entwickler, schnelles Setup |
| llama.cpp | CPU-Inference, Edge-Geräte, GGUF-Modelle |
| OpenWebUI | Browser-basiertes Chat-Frontend (kann mit vLLM verbunden werden, siehe Teil 5) |
Das primäre Unterscheidungsmerkmal: PagedAttention verwaltet den KV-Cache wie virtuellen Speicher und erlaubt es, dass gleichzeitige Anfragen mehrerer Clients sich GPU-Speicher effizient teilen. Ollama ist die einfachere Wahl für einen Entwickler, der ein Modell lokal auf einem Laptop laufen lässt. vLLM ist für einen geteilten Server-Endpunkt konzipiert — es übernimmt Batching und KV-Cache-Scheduling automatisch, was das Queue-basierte Autoscaling in Teil 4 überhaupt erst funktionieren lässt.
vLLM unterstützt keine GGUF-Modelle (das Format von Ollama und llama.cpp). Es arbeitet mit dem nativen HuggingFace-Format, AWQ und GPTQ.
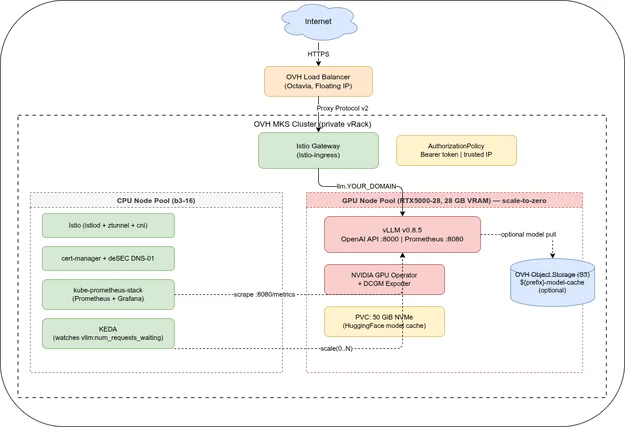
Architektur🔗
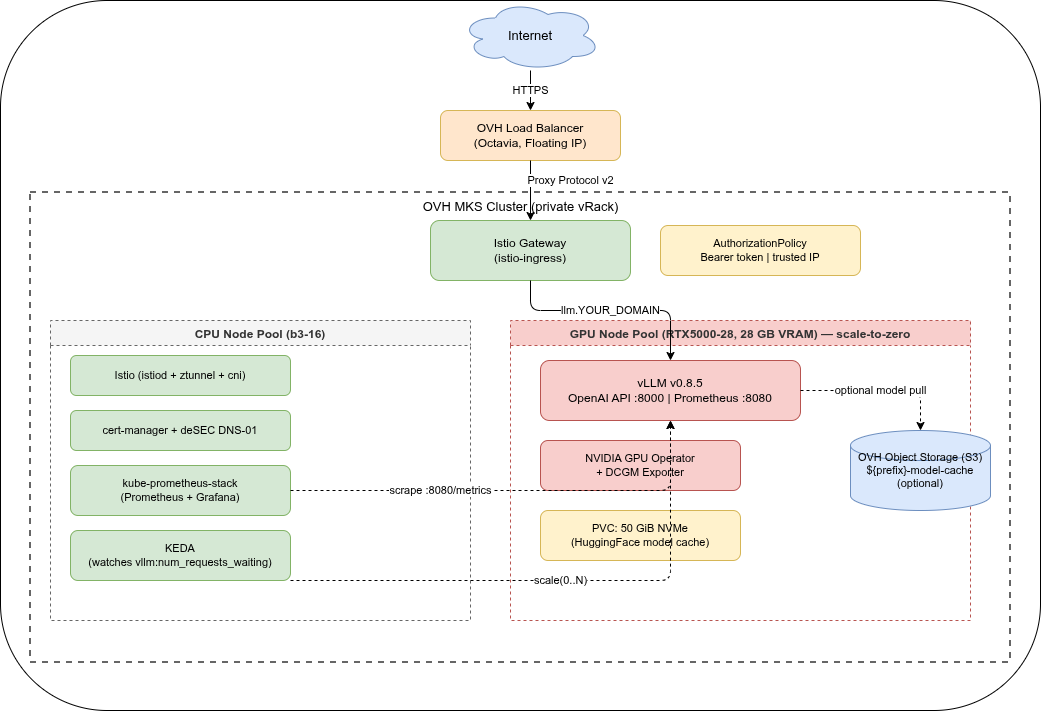
Stack auf einen Blick🔗
| Komponente | Tool | Version |
|---|---|---|
| Kubernetes | OVH MKS | 1.35 |
| Service Mesh | Istio Ambient Mode | 1.30.0 |
| LLM-Inference | vLLM | v0.21.0 |
| GPU | OVH RTX5000-28 | 16 GB VRAM (Quadro RTX 5000) |
| Autoscaling | KEDA | 2.16.0 (Teil 4) |
| Monitoring | kube-prometheus-stack | 65.0.0 (Teil 4) |
| Ingress | Istio Gateway API | TLS via Let’s Encrypt + deSEC DNS-01 |
Zwei Node-Pools🔗
Der Cluster nutzt zwei getrennte Node-Pools:
- CPU-Worker (
b3-16, min 1 / max 3) — Istio, cert-manager, Prometheus, KEDA. Immer mindestens ein laufender Node. - GPU-Pool (
RTX5000-28, min 0 / max 2) — nur vLLM. Startet bei null und wird von KEDA bei Bedarf provisioniert, sobald Inference-Anfragen anstehen. Hinweis: Die “28” im Flavor-Namen ist System-RAM (28 GB); die GPU selbst hat 16 GB VRAM.
GPU-Nodes in einem dedizierten Pool mit einem Kubernetes-Taint (nvidia.com/gpu=present:NoSchedule) zu halten stellt sicher, dass dort nur vLLM-Workloads landen. Plattform-Pods bleiben auf CPU-Nodes und werden nie verdrängt, um Platz für GPU-Workloads zu schaffen.
Produktionsreife🔗
Dieses Setup ist ein produktionsreifer Ausgangspunkt, aber Folgendes sollte man bedenken:
- Mehrere Replicas —
replicas: 2im Deployment setzen für Rolling Updates ohne Downtime (erfordert 2 GPU-Nodes) - Resource-Quotas — eine LimitRange für den
vllm-Namespace hinzufügen, um versehentliche Überprovisionierung zu verhindern - HuggingFace-Rate-Limits — für hochverfügbare Deployments den Modell-Cache-PVC vorab befüllen oder einen S3-Mirror nutzen
- Audit-Logging — vLLM-Request-Logging an eine ClickHouse-Senke anbinden (gleiches Muster wie die Access-Logs-Serie)
- GPU-Sharing — wer mehrere kleine Modelle auf einem einzelnen GPU-Node laufen lassen möchte: Das NVIDIA Device Plugin unterstützt zeitgeschnittene GPU-Zuweisung (
time-slicing-Konfiguration im GPU Operator). Time-Slicing teilt VRAM zwischen Pods auf und bringt Context-Switch-Overhead mit sich — nur praktikabel für leichtgewichtige Modelle (≤5 GB je, z. B. ein quantisiertes 3B-Modell). Für harte Speicherisolation zwischen Workloads ist MIG (Multi-Instance GPU) das richtige Werkzeug, erfordert aber eine A100 oder H100 — die RTX5000-28 unterstützt kein MIG. Für ein einzelnes Modell mit vollem Durchsatz bleibt eine dedizierte GPU pro Pod die bessere Wahl.
Weiter: Teil 2 behandelt die Terraform-Node-Pool-Konfiguration und das vollständige Ansible-Rollen-Setup. Teil 3 behandelt, welche Modelle auf die 16 GB GPU-VRAM der RTX5000-28 passen und wie man die OpenAI-kompatible API aus Python nutzt.
Fragen oder Feedback zu dieser Serie? Gerne melden unter al-vllm@none.at.
Serie
LLM Inference on OVH MKSWann sich Self-Hosting eines LLM auf Kubernetes lohnt, warum vLLM, und wie der Stack auf OVH MKS aussieht. Use Cases, Kosten, Architektur. Teil 1 von 6.