K8s & OpenShift: Das große Bild
Dies ist der Auftakt einer siebenteiligen Serie zu Kubernetes- und OpenShift-Best-Practices, geschrieben aus der Perspektive von 2026 und acht Jahren praktischer Erfahrung — vom ersten Cluster-Design bis zu Day-2-Betrieb und Produktions-Debugging. Dieser erste Teil ist bewusst nicht-technisch: es geht darum, ob und wann sich eine Container-Plattform überhaupt lohnt — die Entscheidungen, die getroffen werden sollten, bevor jemand ein einziges YAML-Manifest schreibt.
Das ist die deutsche Ausgabe vom englischen Teil 1 — K8s & OpenShift: The Big Picture.
Serien-Navigation: Die restlichen Teile dieser Serie sind aktuell nur auf Englisch verfügbar.
- Vollständiger Guide: The Kubernetes & OpenShift Best Practices Guide (2026 Edition)
- Teil 1 — Das große Bild (dieser Beitrag)
- Teil 2 — Workloads richtig bauen
- Teil 3 — Ressourcenmanagement im Detail
- Teil 4 — Skalierung & Resilienz
- Teil 5 — Security
- Teil 6 — Day-2-Betrieb & GitOps
- Teil 7 — Compliance (regulatorische Rahmenwerke, Audit-Logging, Log-Aufbewahrung)
Die technischen Teile sind Kubernetes-first, mit OpenShift-, OVH-MKS- und STACKIT-SKE-Spezifika, wo sie relevant werden.
Eine Anmerkung zur spezifischen Kubernetes-Distribution vorab: OpenShift ist die Distribution, die in dieser Serie namentlich genannt wird — nicht Rancher, VMware Tanzu oder andere Kubernetes-Distributionen. Das ist nicht wertend, sondern hat den einfachen Grund, dass Vanilla-Kubernetes und OpenShift die beiden Plattformen sind, die ich tatsächlich lange genug produktiv betrieben habe, um mit Zuversicht darüber zu schreiben. Wer Rancher, Tanzu oder etwas anderes betreibt: Die Vanilla-Kubernetes-Praktiken dieser Serie gelten trotzdem direkt — es fehlen nur die plattformspezifischen Hinweise für die eigene Distribution.
Kubernetes ist jetzt Standard — und das ist Fakt🔗
Vor einem Jahrzehnt war der Betrieb von Kubernetes keine leichte Aufgabe. 2026 ist es in vielen Fällen Alltag. Viele Cloudanbieter bieten eine Managed-Control-Plane an, die APIs haben sich stabilisiert, und das Ökosystem hat sich auf eine Handvoll gut verstandener Muster konsolidiert. Ein faktischer Standard ist etwas, auf das man sich verlassen und aufbauen kann.
Der Reifegrad der Installationsprozeduren und der Betriebsstabilität von Kubernetes ermöglicht es, gewisse Fragen gar nicht mehr stellen zu müssen. Es geht nicht mehr um “sollten wir Container einsetzen?” — diese Debatte ist für serverseitige Software weitgehend entschieden. Die Frage, die man sich eigentlich stellen sollte, ist “können wir das gut betreiben?” Ein Cluster, der technisch funktioniert, aber keine Resource-Limits, keine Netzwerk-Policies und keinen Upgrade-Plan hat, funktioniert zwar, aber wie geht es danach weiter? Für ein produktives System reicht nicht “es funktioniert” — dazu gehört viel mehr.
Diese Serie handelt vom Unterschied zwischen den beiden Fragen. Dieser erste Teil soll helfen, für den Use Case (also genau dein Fall) relevante Fragen zu stellen, um Entscheidungen rational und nachvollziehbar zu dokumentieren, um dann für sich zu entscheiden, welchen Weg man einschlagen will. Die Entscheidungen hier werden vermutlich direkten Einfluss auf zukünftige Kosten und Lösungen haben.
Warum Best Practices ein Business-Thema sind, kein technisches🔗
Es ist verlockend, “Best Practices” “nur” unter Engineering-Gesichtspunkten zu betrachten — etwas, das das Team ohne Zutun des Managements regeln sollte. Diese einschränkende Sichtweise ist meiner Meinung nach zu eng, denn jede Entscheidung auf technischer oder Business-Seite hat Einfluss auf die jeweils andere Seite. Jeder Teil in dieser Serie betrifft direkt oder indirekt auch das Geschäftsergebnis:
- Zuverlässigkeit zahlt auf Umsatz und Reputation ein. Ein Ausfall zur Stoßzeit kann messbare finanzielle Kosten und Reputationsverluste haben. Einstellungen wie Health-Probes, Disruption-Budgets und sinnvolle Replica-Zahlen (Teile 2 und 4) sind keine Engineering-Eitelkeit — sie halten das Service am Laufen, wenn um 3 Uhr nachts ein Node stirbt.
- Security zahlt auf das Risiko fürs Unternehmen ein. Ein falsch konfigurierter Container, der als Root läuft und keine Netzwerk-Policy hat, ist ein möglicher Sicherheitsvorfall, den es zu vermeiden gilt. Die Konsequenzen eines Fehlers hier sind regulatorisch, finanziell und reputationsschädigend zugleich.
- Ressourcenhygiene zahlt direkt auf die Cloud-Rechnung ein. Workloads ohne Resource-Requests und -Limits sind die häufigste Ursache für Cloud-Verschwendung — überprovisionierte “sicherheitshalber”-Kapazität, die nie jemand richtig dimensioniert. Das ist der FinOps-Aspekt, und er ist groß genug, um ein eigenes Team zu finanzieren; das Business Case dazu steht ausführlicher in Teil 3.
- Operative Reife zahlt auf Team-Geschwindigkeit ein. Teams, die deklarativ deployen und automatisch von Fehlern lernen, liefern Features. Teams, die gegen die Plattform kämpfen, sind primär damit beschäftigt, gegen das System zu kämpfen — das ist nicht sehr effizient und kann zu einer gewissen Unruhe im Team führen.
Keiner der Punkte oben erfordert es, dass eine Führungskraft YAML liest. Sie erfordern jemanden, der entscheidet, dass diese Konzepte und Einstellungen wichtig sind, und dass das Team die Zeit dafür bekommt, sich mit dem System und dessen Eigenheiten vertraut zu machen. Ein wichtiger Aspekt sind die automatischen Checks, die die Einstellungen und Konfigurationen verifizieren, ob das definierte Setup auch das laufende Setup ist.
Wann man Kubernetes nicht einsetzen sollte🔗
Eine Best-Practices-Serie über Kubernetes sollte nicht nur erklären, wie man einen Container-Orchestrator richtig einsetzt. Sie sollte auch klar benennen, wann ein vollständiger Kubernetes-Cluster unnötige Komplexität erzeugt und eine einfachere Lösung die bessere Wahl ist.
Kubernetes hat, wie jede Cluster-Software, echte operative Aufgaben mit sich: Jemand muss Upgrades, Security-Patching, Kapazität und das Plattformwissen selbst verantworten. Dieser Aufwand lohnt sich, wenn man genug Workloads vorhanden hat, um sie zu amortisieren. Das ist ein Overkill, meiner Meinung nach, wenn:
- Das Team klein und die Anwendung einfach ist. Eine einzelne Web-App mit Datenbank braucht keinen Cluster. Eine Managed Platform-as-a-Service (PaaS) oder ein paar VMs hinter einem Load Balancer sind günstiger im Betrieb und deutlich einfacher zu verwalten.
- Niemand Day-2 verantwortet. Wenn niemand dafür zuständig ist, die Plattform nach dem Launch up and running zu halten, veraltet ein ungewarteter Cluster und kann mit der Zeit zum Risiko werden. Ein Managed Service, der diese Last abnimmt, ist die ehrlichere Wahl.
- Die Workload wirklich serverless ist. Spitzenlastige, event-getriebene oder Batch-Workloads mit langen Ruhephasen passen oft besser zu Functions oder Managed-Container-Run-Diensten als zu einem dauerhaft laufenden Cluster.
Wenn du die Person oder das Team nicht nennen kannst, das die Security-Patches des nächsten Quartals und das nächste Kubernetes-Versions-Upgrade anwendet, bist du noch nicht bereit, einen Cluster selbst zu betreiben. Das ist kein Versagen — es ist ein Grund, sich ein Managed-Angebot anzusehen, das das für dich übernimmt.
Containerisieren unabhängig von der Orchestrator-Entscheidung🔗
Die Entscheidung oben betrifft Orchestrierung — ob man Kubernetes braucht, um Container über eine Flotte von Maschinen zu planen, zu skalieren und up and running zu halten. Das ist eine andere Frage, als ob man die Anwendung überhaupt als Container-Image paketieren sollte. Diese zweite Entscheidung sollte fast immer Ja lauten, unabhängig von der ersten.
Ein Container-Image ist eine portable, in sich geschlossene Einheit: die Anwendung, ihre Laufzeitumgebung und ihre Abhängigkeiten, einmal gebaut und überall identisch lauffähig, wo eine Container-Runtime existiert. Das schließt eine einzelne VM ein — Linux, macOS oder Windows — ganz ohne Orchestrator. docker run oder podman run auf einer Box ist ein völlig legitimes Deployment-Ziel für eine kleine Anwendung.
Der Grund, trotzdem zu containerisieren, ist Wartbarkeit, nicht Skalierung:
- Die Umgebung ist reproduzierbar. “Läuft auf meiner Maschine” ist nicht mehr nur ein Test- oder Debugging-Grund, sondern ein echter Check, ob das Ding rennt, weil die tatsächliche Laufzeitumgebung der Maschine mit dem Artefakt mitreist.
- Deployments werden zum einfachen Artefakt-Austausch. Ein Rollback bedeutet, den vorherigen Image-Tag zu ziehen, nicht einen handgepflegten VM-Zustand zu rekonstruieren.
- Der spätere Weg zu einem Orchestrator ist kostenlos. Eine Anwendung, die bereits als Container läuft, hat den schwierigen Teil der Einführung von Kubernetes, OpenShift oder einem Managed-Container- Dienst schon erledigt. Eine Anwendung, die weiterhin per Dateikopie auf eine VM deployt wird, nicht.
- Patchen des Betriebssystems und Patchen der Anwendung entkoppeln sich. Eine VM sammelt über Jahre von In-Place-Updates OS-seitigen Drift an. Ein Container-Image wird bei jedem Release aus einer bekannt sauberen Basis neu gebaut — es gibt keinen mehrjährigen Drift, der sich ansammeln kann.
Nichts davon erfordert Kubernetes. Es erfordert ein Containerfile (oder Äquivalent) und die Disziplin, das gebaute Image statt des Source-Trees auszuführen. Teil 2 behandelt, wie man dieses Image gut baut; dieser Punkt hier ist lediglich, dass die Frage “sollte ich containerisieren” und die Frage “sollte ich mit Kubernetes orchestrieren” unabhängig voneinander sind, und die erste ist 2026 selten diskussionswürdig.
Kubernetes vs. OpenShift vs. Managed Services🔗
Wenn eine Container-Plattform die richtige Entscheidung ist, folgt als nächstes die Frage, welche. Die Landschaft 2026 gliedert sich in drei grobe Optionen, und die richtige Antwort hängt vollständig vom eigenen Kontext ab — Teamgröße, Compliance-Anforderungen, bestehende Cloud-Verpflichtungen und wie viel von der Plattform man selbst besitzen will.
| Dimension | Vanilla Kubernetes (self-managed) | Managed Kubernetes (EKS / AKS / GKE / OVH MKS / STACKIT SKE) | OpenShift (inkl. ARO / ROSA) |
|---|---|---|---|
| Control-Plane-Eigentum | Du | Provider | Provider oder du, je nach Edition |
| Setup-Aufwand | Hoch | Niedrig | Niedrig bis mittel |
| Eingebaute Meinungen | Minimal — du baust den Stack selbst | Minimal — du baust den Stack selbst | Stark — CI/CD, Registry, Monitoring, Auth inklusive |
| Standard-Sicherheitshaltung | Permissiv — du härtest selbst | Permissiv — du härtest selbst | Restriktiv per Default (SCCs, Non-Root erzwungen) |
| Vendor-Lock-in | Niedrig | Mittel (Provider-Integrationen) | Mittel bis hoch (plattformspezifische Objekte) |
| Lizenzkosten | Keine (nur Infra) | Keine über Infra + Control-Plane-Gebühr hinaus | Subscription zusätzlich zur Infra |
| Typische Passform | Teams, die volle Kontrolle wollen | Teams, die K8s ohne Control-Plane-Verantwortung wollen | Unternehmen, die eine Batteries-Included-Plattform wollen |
Ein paar ehrliche Beobachtungen statt eines Urteils:
- Managed Kubernetes nimmt die schwierigste operative Last ab — die Control-Plane — während man weiterhin für Workloads und Add-ons verantwortlich bleibt. Für die meisten Teams, die heute Kubernetes einführen, ist das der Weg mit der geringsten operativen Steuer.
- OpenShift tauscht Flexibilität gegen eine vorkonfigurierte, integrierte Plattform mit einer strengeren Sicherheits-Baseline ab Werk. Ihre Defaults erzwingen mehrere Dinge, die diese Serie im Einzelnen beschreibt. Auf Vanilla-Kubernetes ist das manuell zu konfigurieren. Das kann ein Vorteil sein, wenn die Voreinstellungen zu den eigenen Anforderungen passen. Da OpenShift auch konfigurierbar und flexibel ist, kann man vieles anpassen.
- Vanilla self-managed Kubernetes gibt maximale Kontrolle und minimale Lizenzkosten, zum Preis, alles selbst zu besitzen und alles selbst zu machen — einschließlich der Teile, die leicht vernachlässigt werden. Vor der Installation sollten architektonische Entscheidungen getroffen werden, die Managed-Provider und OpenShift bereits für einen beantwortet haben: CNI-Plugin, Ingress-Controller, Storage-Provisioner, Zertifikatsverwaltung und mehr. Es gibt keine falsche Antwort, aber auch keinen Default.
“Managed-Control-Plane” ist das eigentliche, was angeboten wird bei den Kubernetes-Services — die eigentlichen Maschinen (Worker Nodes) sind meistens nicht im Angebot dabei!
Es gibt hier keine einzelne beste Option; es gibt nur die Option, die zu Team und Rahmenbedingungen passt. Der Rest dieser Serie ist so geschrieben, dass die Einstellungen unabhängig davon gelten, in welcher Zeile man landet.
OVH (ein französisches Unternehmen) und STACKIT (Schwarz Digits, Teil der Schwarz Gruppe) haben ihren Sitz in der EU und unterliegen, anders als die drei großen US-Hyperscaler, in der Regel nicht auf dieselbe Weise direkt dem US CLOUD Act — wobei die genaue Reichweite von Unternehmensstruktur und Jurisdiktion abhängen kann, also eine Frage für den Rechtsbeistand ist, keine pauschale Garantie. Für Organisationen, die NIS2, DORA oder DSGVO unterliegen und bei denen Datenresidenz und Souveränität eine Rolle spielen, reduziert ein EU-ansässiger Anbieter diese Compliance-Komplexität spürbar. Beide Plattformen betreiben ausschließlich EU-Rechenzentren.
Zertifizierungen im Überblick:
| OVH MKS | STACKIT SKE | |
|---|---|---|
| ISO 27001 | ✓ | ✓ |
| SOC 2 Type II | — | ✓ |
| BSI C5 | — | ✓ |
| HDS (französische Gesundheitsdaten) | ✓ | — |
| SecNumCloud | In Arbeit | — |
Die Compliance-Implikationen — insbesondere für NIS2 und DORA — werden in Teil 7 behandelt.
Über die ganze Serie hinweg markieren OpenShift-Hinweise wie dieser, wo sich die Plattform anders verhält als Vanilla-Kubernetes — zum Beispiel Security Context Constraints (SCCs) statt Pod Security Admission, Route-Objekte statt Ingress, das oc-CLI neben kubectl, und Projects statt reiner Namespaces. Mehrere “Best Practices” auf Vanilla-Kubernetes sind auf OpenShift schlicht der Standard.
Team-Bereitschaft zählt mehr als die Technologiewahl🔗
Der häufigste Grund, warum eine Kubernetes-Einführung nicht als erfolgreich betrachtet wird, ist kein technischer. Es ist, dass die Organisation die Plattform eingeführt hat, ohne die Betriebsteams mit einzubinden, welche die Plattform betreiben sollen.
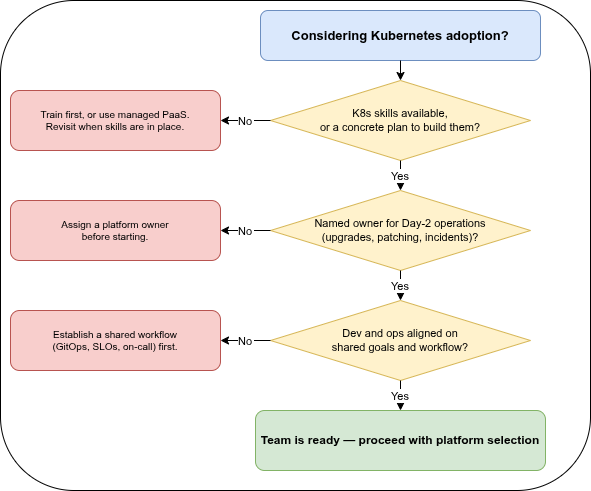
Drei Fragen, die es sich lohnen wird, ehrlich zu beantworten, bevor man sich festlegt:
- Haben wir die Skills, oder einen Plan, sie aufzubauen? Kubernetes hat eine echte Lernkurve. Das Gegenteil vorzutäuschen führt zu Clustern, die per Trial-and-Error konfiguriert werden — genau so setzen sich die Anti-Patterns unten fest.
- Wer verantwortet die Plattform nach dem Launch? Day-2-Betrieb — Upgrades, Patching, Kapazität, Incident Response — ist dort, wo die Kosten tatsächlich anfallen. Eine Plattform ohne Eigentümer verfällt leise.
- Sind Entwicklung und Betrieb aufeinander abgestimmt? Wenn die Menschen, die die Anwendung schreiben, und die, die sie betreiben, unterschiedliche Ziele und keinen gemeinsamen Workflow haben, wird die Plattform zum Schlachtfeld statt zur Erfolgsgeschichte.
Organisatorische Anti-Patterns🔗
Ich habe in den letzten Jahren immer wieder diese Muster bei Kunden beobachten können, unabhängig davon, welche Plattform gewählt wurde:
- Lift-and-Shift ohne Neuarchitektur. Einen Monolithen unverändert in einen Container zu verschieben, gibt einem die gesamte Komplexität von Kubernetes und keinen seiner Vorteile. Container belohnen Anwendungen, die schnell starten, horizontal skalieren und jederzeit gestoppt werden können.
- Keine CI/CD-Pipeline. Änderungen manuell auf einen Cluster anzuwenden skaliert nicht und hinterlässt keinen Audit-Trail. Deklarative, automatisierte Auslieferung ist fundamental, nicht fortgeschritten — das ist Thema von Teil 6.
- Vendor-Lock-in aus Versehen. Sich unbemerkt auf die proprietären Features eines einzelnen Anbieters zu verlassen, macht einen künftigen Wechsel teuer. Lock-in ist nicht per se falsch — OpenShift zum Beispiel tauscht Portabilität gegen eine integrierte Plattform, und das ist eine legitime Wahl. Das Anti-Pattern ist nicht der Lock-in selbst, sondern hineinzustolpern, ohne die Konsequenzen abzuwägen.
- Dev/Ops-Fehlausrichtung. Wenn Entwickler Artefakte über eine Mauer werfen und Operatoren nur an Stabilität gemessen werden, verstärkt die Plattform die Reibung, statt sie zu beseitigen.
Im Prinzip sind das die klassischen Themen, die man auch auf klassischen Systemen hat, man sollte, nur weil man Container hat, nicht die bisherigen Erfahrungen und das bisherige Wissen über Bord werfen. Denn egal ob Container oder installierte Software, am Ende ist alles nur ein Prozess auf einer Maschine, virtuell oder bare-metal 😃
Die sechs Säulen — und der Rest dieser Serie🔗
Was heißt eigentlich “es gut zu betreiben”? Es gibt von einigen Anbietern “Cloud-Well-Architected-Frameworks”, die durchaus sehr hilfreiche Ansätze bieten, und meiner Meinung nach sollte man sich die eine oder andere Architektur genauer anschauen, jedoch immer mit im Hinterkopf “Was brauche ich” und “Wo will ich hin”. Ich hab mal diese sechs Säulen herausgeschrieben, die jede Produktionsplattform adressieren sollte.
| Säule | Die Frage, die sie beantwortet | Wo diese Serie sie behandelt |
|---|---|---|
| Zuverlässigkeit | Bleibt es am Laufen, wenn etwas ausfällt? | Teil 2 & Teil 4 |
| Security | Ist es gegen Angriffe verteidigbar? | Teil 5 |
| Kosten | Zahlen wir für das, was wir tatsächlich nutzen? | Teil 3 & Teil 6 |
| Operative Exzellenz | Können wir es sicher ändern und uns schnell erholen? | Teil 6 |
| Performance-Effizienz | Nutzt es Ressourcen unter Last sinnvoll? | Teil 3 & Teil 4 |
| Compliance & Regulatorik | Kann man es nachweisen — gegenüber Auditor, Regulator, Kunde? | Teil 7 |
Die verbleibenden sechs Teile gehen diese Themen aus Praktiker-Sicht durch:
- Teil 2 — Workloads richtig bauen: Image-Hygiene, als Non-Root laufen, die drei Arten von Health-Probe, geordnetes Herunterfahren und die Erwartungen, die Kubernetes an jeden Pod stellt.
- Teil 3 — Ressourcenmanagement im Detail: wie Requests und Limits tatsächlich funktionieren, cgroups v1 versus v2 (v1 ist 2026 auf dem Weg zum Auslaufen), Quality-of-Service-Klassen, und was wirklich passiert, wenn ein Container sein Memory-Limit erreicht.
- Teil 4 — Skalierung & Resilienz: horizontale und vertikale Autoskalierung, Pod Disruption Budgets, Topology Spread und Anti-Affinity.
- Teil 5 — Security: RBAC, Pod Security Admission (und OpenShifts SCCs), Netzwerk-Policies und Supply-Chain-Kontrollen wie Image-Scanning und -Signierung.
- Teil 6 — Day-2-Betrieb & GitOps: deklarative Auslieferung, Drift-Erkennung, Observability, Kostenkontrolle und Upgrades.
- Teil 7 — Compliance: K8s-Kontrollen auf NIS2, DORA, PCI-DSS, HIPAA und den Cyber Resilience Act abbilden; Audit-Logging als Nachweis; Anforderungen an die Log-Aufbewahrung und wie die technische Umsetzung in der Praxis aussieht.
Der rote Faden ist einfach: 2026 ist der schwierige Teil von Kubernetes nicht, es zum Laufen zu bringen. Es ist, es gut zu betreiben — sicher, bezahlbar und ohne Überraschungen. Ein Teil von “es gut zu betreiben” ist eine Frage, die die meisten Teams überspringen: Ist die Anwendung selbst tatsächlich für die typischen Laufzeit-Eigenheiten von Kubernetes ausgelegt — abruptes Beenden, flüchtiger lokaler Storage, keine garantierte Startreihenfolge, jederzeitige Skalierung und Neuplanung — oder ist es eine VM-förmige Anwendung, die zufällig in einem Container läuft? Darum geht es im Rest dieser Serie.
Und am Ende des Tages soll Kubernetes dem Unternehmen die Möglichkeit bieten, sich auf seine Kernkompetenz zu konzentrieren und die Flexibilität zu erhöhen, und nicht die Teams mit Infrastruktur-Tätigkeiten zu beschäftigen.
Weiter: Teil 2 behandelt den richtigen Bau von Workloads — Image-Hygiene, als Non-Root laufen, die drei Arten von Health-Probe und geordnetes Herunterfahren.
Teilweise verwendete Quellen — spezifische Referenzen erscheinen in den jeweiligen Teilen.
- Kubernetes resource limits and kernel cgroups — Medium (2019)
- Best practices for running apps in Kubernetes — Part 1 — Palark (2021)
- Best practices for running apps in Kubernetes — Part 2 — Palark (2021)
- Cgroups — Deep Dive into Resource Management in Kubernetes — Martin Heinz (2023)
- About cgroup v2 — kubernetes.io (2025)
- Kubernetes Best Practices I Wish I Had Known Before — Pulumi (2025, updated 2026)
- 17 container security best practices for 2026 — Sysdig (2026)
- Kubernetes security 101: 10 best practices and fundamentals — Sysdig (2026)
- Kubernetes production readiness checklist — learnkube.com (2026)
- Kubernetes Best Practices for Safer, More Reliable Clusters — Komodor (2026)
- Architecture Best Practices for Azure Container Apps — Microsoft Azure Well-Architected Framework (2026)
- kubernetes-best-practices — Diego Lima, Apache-2.0
- What Are cgroups in Kubernetes? — Zesty
Serie
Kubernetes & OpenShift Best Practices in 2026Kubernetes ist 2026 in vielen Fällen Standard — die eigentliche Frage ist, ob man es gut betreibt. Wann K8s oder OpenShift passt, wann nicht. Teil 1 von 7.